Last month I started wrangling with JSON in SSIS and discussed how to download JSON files and store them as flat files. Now I want to move that data into staging tables in SQL Server.
My general philosophy about staging tables is to move the data into tables while preserving the original structure and contents of the data as well as possible. In this case, I’m slightly bending my own rule by selecting a specific array from each JSON file because this is where the majority of the data resides. In my PBIX files that I created at the beginning of this series, I also eliminated the JSON objects that are on the same level of the array, so I already know I don’t care about these bits of data.
Here’s the general plan for staging the data:
- Create a staging table for each group of files–games, player, etc.
- Read each JSON file using OPENJSON and insert the results into the target staging table.
Create a staging table
I need one staging table for each type of file that I have. I already have a list of 5 of the 6 types of tables in the apiCall table that I built (described here), so I can use an Execute SQL Task to generate this list and use UNION to append the 6th table type to the list manually.
select querytype from dbo.apicall union select 'seasons'
I set the ResultSet property of the task to FullResultSet. On the Result Set page, I assign the Result Name to an object variable, tableNameSet.
Then, I can use a Foreach Loop Container to iterate through tableNameSet by using the Foreach ADO Enumerator, and map the single column it contains to a string variable, tableName.
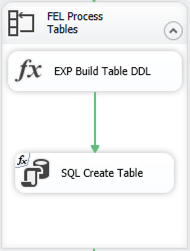
Each iteration of the loop will use an Expression Task to build the DDL necessary to create the staging table and then use an Execute SQL Task to execute the DDL.
By using the OPENJSON function to read the JSON files, I’m guaranteeing the structure of each staging file is identical. All I need to do is change the name of the table in my DDL. (Note: I already added a staging schema to my database.) The Expression Task contains the following code:
@[User::tableDDL] = "DROP TABLE IF EXISTS staging." + @[User::tableName] + "; CREATE TABLE staging." + @[User::tableName] + "( [key] nvarchar(4000), [value] nvarchar(max), [type] tinyint )"
Normally I truncate staging tables, but for now I’m ok with dropping the tables if they exist (using syntax applicable to SQL Server 2016 or later) and recreating it. Later, I might expand on my solution by setting up a package for the one-time tasks like creating tables and change this code to perform a truncation, but that will be later.
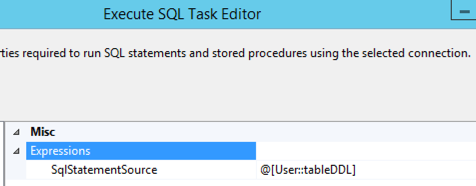
The Execute SQL Task then uses an expression to assign the value of the tableDDL variable to the SqlStatementSource property dynamically at runtime, and voila… the staging tables are created.
Read each JSON file
Now I’m ready to load those tables by reading each of the JSON files using another Foreach Loop container and executing a series of tasks: expressions to set variables, read a table to get the path that I need in the OPENJSON query, and then a Data Flow Task that has its source query set dynamically to a particular JSON file and a target table for which the table name is stored in a variable.
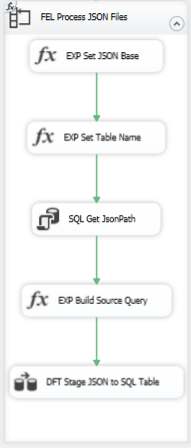
Let’s peel this apart.
The Foreach Loop Container is set to use the Foreach File Enumerator. I changed my user variable filePath from my first package to a project parameter now that I have two packages in my project, and I reference that project parameter in the Directory property expression. I restrict the enumerator to txt files using a wildcard and get the fully qualified name of the file. That way, I can use that value when I build out the OPENJSON query. I map this value to a string variable, sourceFile.
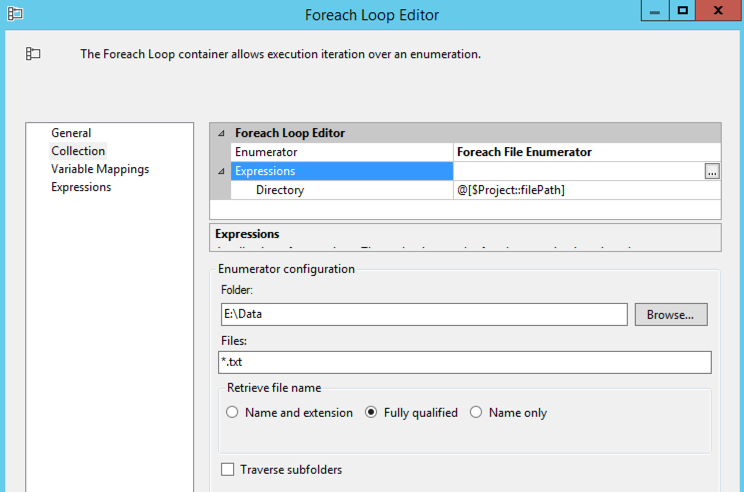
Inside the loop, my first two steps are to use Expression Tasks to set variable values.
First:
@[User::jsonFileNameBase] = REPLACE(TOKEN(REPLACE(@[User::sourceFile], @[$Project::filePath] + "\\", ""), "_", 1), ".txt", "")
Basically, this code strips out the path from the fully qualified name and gets the base name of the file that precedes the underscore in the name. For example, the file e:\data\games_19171918.txt is transformed to games by this code. However, I also have files like seasons.txt that have no underscore, so I need to strip off .txt to get to the desired base name of seasons.
Second:
@[User::tableName] = "staging." + @[User::jsonFileNameBase]
Here I prepend the schema name to the base name created in the first step to assign a table name to a variable.
Then I set up a table manually to hold the path value I need for the OPENJSON table. Nothing fancy – I just need a way to map paths to file types:
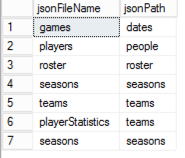
I use an Execute SQL Task to query this table. By using a parameter in the query, I can call this task to query for the current file type:
select jsonPath from jsonPath where jsonFileName = ?
The parameter mapping looks like this:

I set the ResultSet property to SingleRow as there will only be one result and I assign this result set to the string variable jsonPath.
One more Expression Task is necessary. This final task uses the sourceFile and jsonPath variables to build out the string variable sourceQuery:
@[User::sourceQuery] = "DECLARE @jsonValues VARCHAR(MAX); SELECT @jsonValues = BulkColumn FROM OPENROWSET (BULK '" + @[User::sourceFile] + "', SINGLE_CLOB) as j; SELECT * FROM OPENJSON(@jsonValues, '$." + @[User::jsonPath] + "');"
The last step is to call the Data Flow Task which consists of two components, an OLE DB Source and an OLE DB Destination.
The OLE DB Source references the sourceQuery variable created in the previous step.

Last, the OLE DB Destination is set up to target the table specified in the tableName variable:
After executing the package, all the data gets loaded – still as JSON objects – into SQL Server tables. Foreach Loop containers made it easy to loop through table rows in the first set of tasks and through the files themselves in the second set of tasks and to use variables that dynamically change the task properties for each loop iteration. That way, I didn’t have to build a unique Data Flow Task for each type of file that I wanted to load.
Of course, the part that made this easy was that the target table structures were identical so the Data Flow Task column mappings do not change on each iteration. If they did, I would not be able to use this approach.
In my next post, I’ll work through restructuring this data into a relational model that will become the basis for future analytics projects. Stay tuned!
You can download the SSIS solution here.
1 Comment
Hello,
Is the next blog available anywhere yet? I really need to do this, and this is the only (and best) information I can find on it. Really well written by the way.