As I mentioned in my previous post, I’ve been wrangling at lot of JSON lately. And, in my spare time, I’ve been wrangling a lot of hockey data, launching a series of posts that began here.
In fact, since I started working with the hockey data exclusively in Power BI, I’m finding that the refresh process is getting slower and I haven’t even collected all the data that I’d like to analyze yet! Furthermore, I keep thinking of other ways that I would like to use the data outside of Power BI, so I really need to make a separate repository of the data. That’s what I’m up to in today’s post – making a local copy of the files.
Note: I have not yet found the NHL API terms of use explicitly, but I have seen comments made here and there that the non-commercial usage of this data is fine. As I am using this data for demonstration purposes only, I believe I’m in compliance. If I find otherwise, I’ll note it here and adjust my usage accordingly.
Planning the Approach
SQL Server Integration Services (SSIS) is my tool of choice for this task. My initial plan is to get the JSON files and store the files on a local (or network) drive. In future posts, I’ll cover what I can do with local JSON files, but for now I just want to automate retrieving them.
It turns out that I cannot use the OData Source in a Data Flow Task because the NHL data is not exposed as an OData Service. But I still have a simple way to get files from this particular API — use curl.
There are multiple ways to run curl from Windows. At the moment, I’m not interested in debating the merits of one method over another. For now, I’m using the 64-bit version of Cygwin for Windows with the curl package installed.
Downloading JSON
To use curl in SSIS to download the files, I use the Execute Process task configured with a call to the curl executable and passing arguments for the URL I want and the path and filename for the JSON returned by the API call.
Using this general approach, I create an Execute Process task as shown below. I always start with a “hard-coded” version of the operation I want to accomplish before trying to use expressions for dynamic operations so that I can make sure everything works as expected first.
Notice the Arguments property has the URL enclosed in single quotes and the -o flag with a file name to indicate the file into which the data will be saved after downloading. The WorkingDirectory property contains the folder path for the output file.
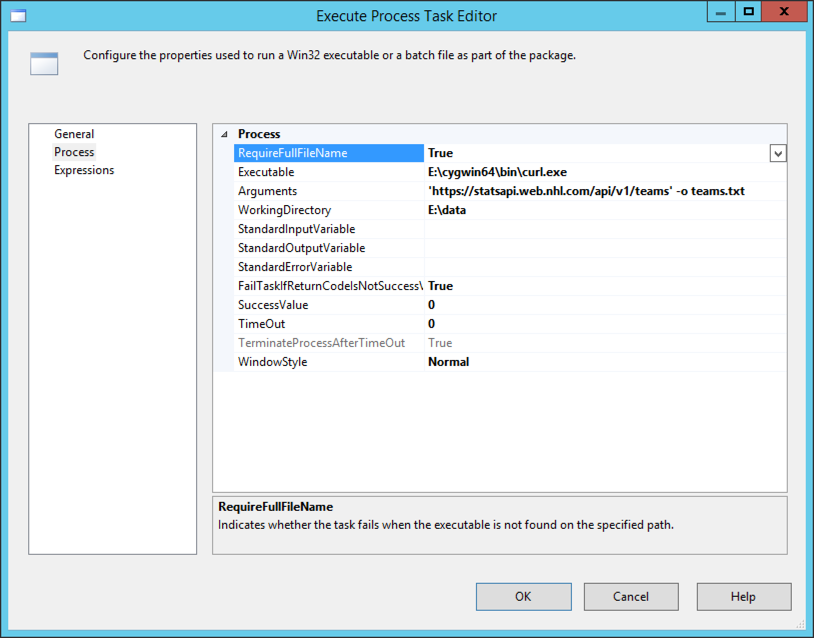
When I execute this task, I get a file where I expect one to land, so all is well.
Except that I am really lazy about creating tasks in SSIS and prefer to figure out a way to automate what I can so that I don’t have to set up a task for every file that I want to download. I need to make a change. That’s where expressions and loops come in handy.
Iterating through the API calls
One of the great features about SSIS is the ability to change behavior at runtime by using dynamic expressions. Rather than set up a task for each API call, I can set up a table, read its rows into a variable, and then use a ForEach loop container to iterate through the rows, create variables for each column in a row, and then use these variables to dynamically build out a URL.
Reviewing my queries that I created in Power BI, I can see that I have different patterns to create. (The context for these patterns is described in the series of posts that begins here). In some cases, I just need to get data from a static URL. In other cases, I need to dynamically generate the URL.
To support the use of the ForEach loop to build the URLs that I need, I created and populated the following table in a SQL Server database:

I’ll use these columns to populate variables that I’ll use in each iteration of the ForEach loop:
- queryType – this value not only identifies the query (for me), but will also be used to create the filename for storing the JSON locally
- urlSuffix1 – this value gets appended to the base URL, https://statsapi.web.nhl.com/api/v1/
- urlSuffix2 – the final string to appended to the base URL following the urlSuffix1 and other values, as applicable
- iterative – a flag to indicate which branch of the control flow to follow
- queryFile – the file on which the query is dependent (e.g. to get roster data, the teams file must be read)
- queryPath – the path to the data to be be retrieved (e.g. to get roster data, read the id from the teams file)
- queryObject – the JSON array to which the query path is applied (e.g. to get roster data, look in the teams array – which is where the id referenced in queryPath is located)
- processOrder – due to dependencies between queries, I need to control the order in which they execute
I also added variables to the package. I describe the use of these variables in the walkthrough of the package.
Then I constructed a package to read the table I created, populate variables, and then use these variables to construct the necessary URLs and output file names in an expression associated with an Execute Process task. Here’s the final package:
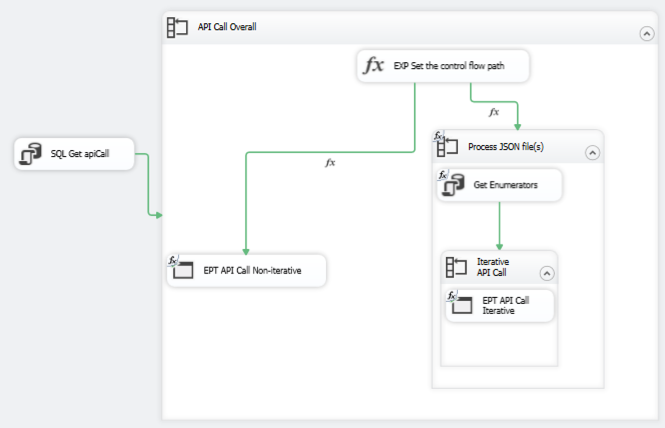
Let me walk you through the specifics of the package:
- SQL Get apiCall: This is an Execute SQL Task that gets the data from the table I created and stores the result in the apiCall variable.
SELECT [querytype], [urlSuffix1], ISNULL([urlSuffix2], '') as urlSuffix2, [iterative], ISNULL(queryFile, '') as queryFile, ISNULL(queryPath, '') as queryPath, ISNULL(queryObject, '') as queryObject, processOrder FROM [dbo].[apiCall] ORDER BY processOrder
- API Call Overall: This is a ForEach loop that iterates through the rowset variable. That is, each row from the table that I created that identifies the different types of queries that I need to execute. I set this loop to use the ADO enumerator and reference the ADO object source variable–apiCall. Then the columns returned by the query are mapped to variables which are used inside the container:
- EXP Set the control flow path: This is a placeholder task. I need a way to control whether I do a single API call (the teams query) or run through the same call iteratively (such as when I need to process each team id individually). I set the expression to 1 == 1 just to have something valid configured for this task. The real goal was to set the precedence constraints to determine which way the control flow will flow…
- One path leads to the EPT API Call Non-iterative. This path has the Expression and Constraint option set with the following expression: !@[User::iterative]. This expression affects the control flow for one query type only, the teams query.
- The other path leads to the Process JSON file(s) loop. This path has the Expression and Constraint option set with the following expression: @[User::iterative]. All other queries will use this control flow path.
- EPT API Call Non-iterative: This is a variation of the Execute Process Task described above. In this case, I’m using expressions to dynamically generate the Arguments and WorkingDirectory values at runtime. The urlSuffix1, urlSuffix2, and queryType variables come from the current iteration of the ForEach loop and I set up the filePath variable to be able to have a single place to reference the location of the JSON files.

- Process JSON file(s): This is a ForEach Loop container that drives looping through a list of files. The list could be a list of one (the teams.txt generated by the EPT API Call Non-iterative task) or a list of many. I’m using the Foreach File Enumerator here with expressions to determine at runtime where to find the files (Directory) and the file specification (such as teams*.txt or roster*.txt, etc.). The file name for each iteration is mapped to the currentFile variable:

- Get Enumerators: This is an Execute SQL Task that reads the data from the dependent JSON file (queryFile). I use an expression to dynamically generate the SQL that gets executed using the variables associated with the current iteration of the API Call Overall loop. This technique takes advantage of the JSON support in SQL Server 2016 or higher to read specific elements out of a JSON file. For example, the first time this task executes, the file to be read is teams.txt (created by the EPT API Call Non-iterative task). The team IDs are extracted from this file and stored in the apiEnum variable as a result set.
"DECLARE @jsonData VARCHAR(MAX); SELECT @jsonData = BulkColumn FROM OPENROWSET(BULK '" + @[User::filePath] + "\\" + @[User::currentFile] + "', SINGLE_BLOB) JSON; SELECT JSON_VALUE([value],'" + @[User::queryPath] + "') as enum FROM OPENJSON(@jsonData, '" + @[User::queryObject] + "');"
- Iterative API Call: This is another ForEach Loop container using the ADO Enumerator to iterate through the rows in the apiEnum variable. The single column in this rowset variable is mapped to the apiEnumValue variable.
- EPT API Call Iterative: This Execute Process task is much like the EPT API Call Non-iterative task. There are two differences. First, this task is executing inside the ForEach Loop container which passes in the apiEnumValue. Second, the expression for the Argument property relies on this apiEnumValue to pass into the URL string and also to uniquely number the JSON file that gets stored locally. As an example, the first roster file based on team ID 1 is saved as roster_1.txt.
"'https://statsapi.web.nhl.com/api/v1/" + @[User::urlSuffix1] + @[User::apiEnumValue] + @[User::urlSuffix2] + "' -o " + @[User::queryType] + "_" + @[User::apiEnumValue] + ".txt"
One little problem…
Everything works great in the package above. However, I did encounter a problem that I need to research.
The one JSON file that I need to iterate through that I cannot get from the NHL API (that I know of) is the list of seasons. In Power BI, I generated a list using the {1917..2017} syntax to use as the basis for building out the 19171918 format required to request data for a specific season. I tried to use a T-SQL statement to generate a JSON document:
DECLARE @seasonStart INT=1917;
DECLARE @seasonEnd INT=year(getdate());
WITH seasonYears AS (
SELECT @seasonStart AS seasonYear
UNION ALL
SELECT seasonYear+1 FROM seasonYears WHERE seasonYear+1<=@seasonEnd
)
SELECT convert(varchar, seasonYear) + convert(varchar, seasonYear + 1) as season FROM seasonYears
option (maxrecursion 200)
for json path, root('seasons');
This statement produces the results I want. No problem here. However, when I use this statement in an OLE DB Source for a Data Flow Task, with the intent of saving the file using a Flat File Destination (as described here), I get a weird file. Everything LOOKS right, except that there’s a stray line feed in the TXT file. I’ve tried outputting as a Unicode file or as a non-Unicode file, but either way the file can’t be read by the code in the Get Enumerators task (which I need to use to loop through the seasons).
After much experimentation, and another pair of eyes (thanks, Kerry Tyler!) , I could see the problem lies in the OLE DB Source component. Something in there is breaking the JSON stream into two rows. A careful review of the screenshots in the post to which I linked in the previous paragraph shows similar behavior, even if the post doesn’t call it out.
Update 2 June 2018: I discovered the reason for this behavior and developed a workaround which you can see here.
Honestly, I don’t really need SSIS to generate the file. It’s a one time thing. So I execute my code in SSMS and use copy/paste to put the results into the season.txt file, and I’m good to go. My package runs fine and I get all the JSON that I want/need downloaded successfully.
For the record, the package took approximately 18 minutes to run and downloaded 1,000 files. On my wimpy little laptop.
Here’s a link to the SSIS package and the code to create the apiCall table.
Mission accomplished for today. Now that I have JSON files, I can do other kinds of fun things with hockey data… Another day!
10 Comments
[…] my last post, I was stymied by a problem in SSIS. My goal was to use a T-SQL statement to generate a set of rows […]
[…] month I started wrangling with JSON in SSIS and discussed how to download JSON files and store them as flat files. Now I want to move that data into staging tables in SQL […]
Hello,
Does your query fetch different api models or same api models?
I don’t see curl, is it called something else now?
Hi George, I’m not sure what you mean by “I don’t see curl…” Its name hasn’t changed. There are many different ways to install and invoke it, but your specific options depend on your operating system. Assuming Windows, for example, check out instructions from a post at Stack Overflow: https://stackoverflow.com/questions/9507353/how-do-i-install-and-use-curl-on-windows
I found putting single quotes around the curl URL argument did not work. Removing the quotes fixed it.
The API I’m using requires authentication. It works from the command line when I add “-u /” for the authentication. But when I try to include the -u argument in the EPT, it opens the command window and pauses, asking for a password. Any ideas on how to work around this password prompt?
If not, I will explore using a Script Task.
Thanks,
Hi,
The API I’m using requires authentication in the form of username/password. It works when I exec the cURL command from a command window. But when I try to include the -u agrument in my Exec Process Task, it stops and prompts me for a password. Any thoughts on how to work around this password prompt?
Thanks,
I’m not in a spot right now where I can look at a task that I’ve used. I can say that I’ve passed in an argument for a password without having it prompt me during execution so there is a way to make it work. So there IS a solution – I just can’t remember off the top of my head. I won’t be able to look until tomorrow morning though.
I’m still not able to get to an actual working package for another day or two as I’m traveling without a laptop at the moment. I did review my notes and it looks like I wrapped the user name and password together in a structure like this:
–user ‘username:password’
I know for certain I didn’t get prompted during execution. I’ll continue to look at this later in the week if this doesn’t help you. Please let me know.