Hockey season is almost over and I’m very excited to see my home team, Vegas Golden Knights, not only make it to the playoffs, but also earn the Pacific Division Championship! An accomplishment no one predicted at the beginning of the season. It’s their inaugural season after all. Who does that? (Go Knights Go!) I’m curious what the data has to say, but I’m jumping ahead of myself.
 |
 |
|---|
After a fair amount of hockey data wrangling and some sanity-checking of the data in Parts 1 through 5 of this series (which starts here if you need to figure out what I’m up to and why), I’m ready to start using data visualizations to continue the data exploration process–this time by focusing on the data distribution.
What’s Distribution?
When I began the first pass through my data, I built tables to explore the “middles” and “ends” and promised that I would explain more about distribution in a future post. Well, that post has arrived!
Let’s start by reviewing where we’ve been. For each of the tables in the Power BI model, I isolated the numeric variables and created table visualizations to display the minimum, maximum, mean (average), and median values for each variable.
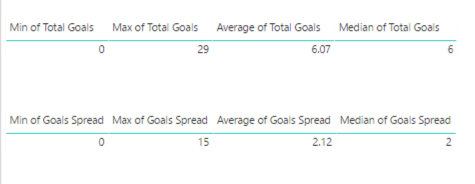
My purpose at the time was to sanity-check the data. And indeed I found some flaws which I need to figure out how to handle because the source data has missing pieces. But the missing data is for a single year and for pre-season games, so for now I’m going to live with it. I’m more interested at the moment in other things, but I have it noted as a to-do item for the future.
By reviewing these four values, I learn about the distribution of the data. In other words, I learn about the range of possible values in my data and how often certain values occur (also known as frequency). The minimum and maximum values tell me about the boundaries of the data values, and potentially clue me into outliers. The mean (average) and median values tell me something about central tendency. That is, what is a “typical” value in this data?
The mean is a commonly used descriptive statistic. It is calculated by summing up all the values in the data set and then dividing the result by the count of all the values.
Median is something you might hear about in demographic statistics – the median home value, the median salary, the median age, etc. It’s calculated by dividing the values into groups where half the values are above a point known as the median and the other half are below this point.
Let’s take a super simple example using a set of values:
1 2 3 4 5
The mean is (1 + 2 + 3 + 4 + 5) / 5 = 3.
And with 5 values, clearly 4 and 5 are in the top half and 1 and 2 are in the bottom half, and 3 straddles the middle. That’s’s the median. Easy peasy.
The value 3 is both mean and median, which tells me there is no skew in this data. It’s symmetrical with values congregating neither at the higher or lower edges of the range of possible values.
Now let’s take another example:
10 11 12 13 14 100
The mean is now 26.67, while the median is 12.5. We have 10, 11, and 12 in the bottom group and 13, 14, and 100 in the top group. The value 12.5 is halfway between 12, the top of the bottom group, and 13, the bottom of the top group.
The difference between the mean and the median also tells me something about the data distribution:
- In the first example, the mean and median values are the same, which indicates there is no distortion in my data. Values are represented relatively equally from low to high.
- In the second example, there is quite a spread between mean and median, which tells me there is some distortion. Some value (or values) is “pulling” the mean in some direction. That’s the outlier’s fault. In this case 100 is a significantly higher value than all the others and it affects the mean. On the other hand, the median of 12.5 discounts that outlier and better reflects the middle of the pack. (Try calculating the mean without the 100 value and you’ll see how much closer the mean and median get.)
When you analyze data by using mean and median, both numbers are useful because they provide clues about the potential presence of outliers. And by looking to see whether mean or median is the higher value of the two, you know something more about the data:
- Mean > Median: A few high values exist while the true middles are lower.
- Mean < Median: A few low values exist while the true middles are higher.
Visualizing Distribution with Histograms
I can get all this information about my data by creating tables and looking at the comparisons one by one. But my brain has to work harder at making the comparisons.
Visualizations to the rescue! A common way to visualize data distribution is to use a histogram.
Power BI does not include a histogram visualization out-of-the-virtual-box. I could create one with some gyrations that would require me to decide how I want to group data and count up the frequencies, but that would be overly tedious for every combination that I want to review.
In this post, I’m going to introduce two options: a custom visual and an R visual. In addition, I’ll describe the pros and cons of each.
Custom Histogram
Power BI provides easy access to visualizations that have been created by Microsoft and third parties. In the videos below, I’m using a cleaned up version of my previous PBIX file – I removed all the report pages in which I was exploring the anomalies discussed in my last post and the post prior to that.
The key steps:
- Add the Histogram visual to the report
- Add Total Goals as Value and Count of Game Name as Frequency to the new visual
- Adjust the number of bins as desired
- Adjust the decimal places on the x-axis to set bins as whole numbers
The pros of using this custom visual:
- It’s easy to install and use
- It behaves like native Power BI visuals
- It allows you to format many (but not all) of the features of the visual
- It responds to filters and slicers like native visuals as shown below
- It can cross-filter other visuals on the page when you click on a bar
- It works fine on the Power BI service
The cons of using this custom visual:
- You cannot format everything you possibly might want to format
- You cannot add other features such as mean and median lines, for example
- You cannot fine-tune the bin definitions
R Histogram
If you know how to use R to generate a histogram, you can create your own code and produce exactly what you want.
Before you start, you do need to configure Power BI options to set your path to the R libraries and the R IDE that you want to use:
In my report, I decided that I want to be able to generate one or more histograms based on the number of numeric fields that I pass to the script. And I want to show mean and median on the histograms. And I want to include summary statistics as well.
I have a lot of wants. With R, I can handle those wants!
The key steps:
- Add the R visual to your report
- Add the fields to pass to the script to the R visual. In my example, I illustrate how to get multiple histograms in one visual by choosing all the numeric fields, Total Goals and Goals Spread, plus the frequency basis, Game Name.
- Launch the R IDE from Power BI to send the selected fields as a dataset
- Test the R script in the R IDE
I can then paste the script into the editor for the R visual in Power BI and run it view the results in my report:
The pros of using the R visual:
- It can be set up in any way that you like by generating multiple items, applying formatting, or adding additional features.
- You can fine-tune the binning any way you like.
- It responds to filters and slicers like any other visual.
- It resizes automatically to fill the allocated space.
The cons of using the R visual:
- You must know some R to be able to use it.
- It cannot take advantage of any custom theme that you might use in the report to standardize color schemes, fonts, etc.
- It cannot be used to cross-filter other visuals on the same page.
- It is not visible in shared reports on the Power BI service unless you and the other users have Power BI pro.
- Not all packages are supported. You can find the current status of R package support here.
Viewing the visuals in the Power BI service
Everything looks fine (mostly) when I publish my report to the Power BI service. (I say mostly because it looks like I stumbled across a bug in the numeric slicer.) Here’s the proof of working visuals:
All is well and good (assuming you’re sharing with Power BI Pro users), unless you want to embed your report in a Web page – whether internally within your organization or externally in a publicly accessible location. If it includes an R visual, you have a problem.
Jump to page 18 to see what I mean. Hint: a fast way to do this is to click the 4 of 18 at the bottom of the report, scroll through the page titles until you see Duplicate of Game Numerical Values, and click that page.
Conclusion
There’s not a right or wrong answer regarding which choice you make for adding a histogram to a report. You just need to know the pros and cons of each choice and go from there.
As for distribution analysis, a histogram is not the only option. There are other types of visualizations that I’ll explore in my next post!
Meanwhile, you can download the PBIX file containing the histograms and the R code if you want to take a closer look.
3 Comments
[…] my next post, I plan to take another pass at the numeric statistics by analyzing the distribution of […]
[…] data can be quite informative about your data set. I’ll get more deeply into distribution in a future post. For now, I want to focus on the middles – which are the average and mean values for the […]
[…] the opposition at the player level. I’m still focused on distribution analysis as I was in my previous post, but now I want to evaluate the numerical variables for specific combinations of teams. (You can […]