The goal of my last two posts was to gather data published by the NHL for hockey teams and players, including the basic statistics available at the team, player, and game level. I was able to put together some tables and charts to answer a burning question I had about what constituted a high-scoring game and to present a player’s career statistics. Now it’s time to continue with Part 3 of this series.
First time here? You can rewind to the beginning of the series by starting here and then following the pointers at the end of each page to the next post in the series.
If you read my last post in which I discuss acquiring and displaying player statistics, you might be wondering what’s the point? Isn’t this data already available at NHL.com? Well, sure – but that was just a stepping stone to the deeper analysis that I want to do.
As a hockey newbie, I have lots of questions! And now I have some data. I plan to use this curiosity about hockey and my data analytics skills to answer questions and understand the data. Even though my examples in this series focus on hockey data, you’ll see that the tools, techniques, and concepts that I cover are also applicable to all sorts of data, business or otherwise. For now, there’s a lot I can do with Power BI, so that’s the tool I’ll continue to use for a while.
So what is data analytics anyway?
When I started my career eons ago, I had never heard of business intelligence (BI), let alone data analytics. But I did spend a lot of time helping people use data to answer questions about their business which ultimately led me to my formal BI career that started in 1998. Even then, I didn’t hear the phrase “data analytics” very often, if ever.
I don’t have any concrete evidence, but my general feeling is that analytics crept into more common usage around the time that the phrase Big Data became more commonplace. Still, I encounter a lot of confusion about what it means.
What does Wikipedia say?
Data analysis, also known as analysis of data or data analytics, is a process of inspecting, cleansing, transforming, and modeling data with the goal of discovering useful information, suggesting conclusions, and supporting decision-making.
Techopedia gets a bit more specific with this definition:
Data analytics refers to qualitative and quantitative techniques and processes used to enhance productivity and business gain. Data is extracted and categorized to identify and analyze behavioral data and patterns, and techniques vary according to organizational requirements. Data analytics is also known as data analysis.
I see my work in business intelligence over the years as enabling processes to ask and answer known questions repeatedly (with varying potential answers over time). Questions like…how much did we sell last month and how does that compare to the prior month, or which customers (or products) are most profitable?
Whereas BI tends to be historical in nature (although one could argue this point), I see work in data analytics as enabling processes to discover interesting patterns in the data that we might not have thought about. These discoveries can then be used to improve upon something, like a business process, or to predict something, such as future sales trends, to name just two opportunities made possible by using data analytics.
With regard to applying data analytics on hockey data, I expect to learn something about the sport that isn’t obvious to me as a newbie when I look at the NHL’s stats page. Today, I’m going to start with the most basic of basic data analytics, exploration.
More tweaks to the Power BI model
Oh – one more thing. Before beginning this post, I made more modifications to the PBIX file I had at the end of the last post.
First, I added in games for all seasons for the past 100 years, using a variation of the technique described in Part 2 in which I loop through a set of rows and call a function. Yes, hockey is 100 years old! Can you believe it?
After converting my games query to a function, I set up a list of values from 1917 to 2017, added a custom column to add 1 to the value, and then concatenated the two values to come up with a string to represent a season, such as 19171918.
In addition to getting games for all seasons, I also added a new custom column to calculate the difference between the away team and home team score and named it Goals Spread. I thought it would be a good value to explore later.
I also updated the scores away and scores home tables to reflect the data for all available seasons instead of using just season 2017-2018. You can review the PBIX file to see how I set up the queries.
I discovered that when I tried to create a relationship between games and scores based on Game ID, I got an error message:
You can’t create a relationship between these two columns because one of the columns must have unique values.
I checked my data in the games table by counting the rows and the number of distinct game IDs and found the numbers matched – 60,884. Very puzzling. Then I looked at the data itself, sorting the Game ID column in ascending order and discovered the culprit – a null Game ID for season 2004-2005. I removed the row and then I was able to create the relationship.
It turns out that season 2004-2005 had no games at all. The entire season was cancelled due to a labor dispute.
Although I didn’t get a similar relationship error for the statistics table, I did note a null category when setting up the report page for the statistics table. After I sorted the table in the Query Editor by season, I found and eliminated the null row for player ID 8480727.
Introducing exploratory data analytics
Technically speaking, I should have started my data analytics project with some basic exploration. But my excitement about getting the data and a burning question at the time that I acquired it led to my first post in this series. Then I needed to validate that I had put together the data correctly by viewing player statistics (as shown in my second post) that I could compare to the official stats.
I’ve poked around a bit in my data enough to have a general sense of what it contains, but now it’s time to do the official exploration. Whenever I get my hands on a new data set, I need to be able to identify specific characteristics about the data.
What is its structure?
In this case, I have transformed JSON documents into a set of tables:
- teams
- scores
- players
- statistics
- games
Each table contains multiple rows and columns. My next step is to evaluate the columns by type.
Which columns represent numerical variables?
A numerical variable (also known as a quantitative variable) is a set of values that first and foremost are numbers. The numbers can represent counts of things, dollar amounts, or percentages, to name a few.
In the games table, I have two numerical variables—Total Goals and Goals Spread.
Which columns represent categorical variables?
A categorical variable is one in which there are a distinct number of values. Often, a categorical variable is a string of characters. The tricky part sometimes is identifying categorical variables that contain numeric values, but really represent a category. These are values that you wouldn’t add up together, such as Season. We can get more nuanced about categorical variables, but that will come in a future post.
The games table has the following categorical variables:
- Game Date
- Game Time
- Game ID – although this is really of no analytical value because it’s a unique identifier for the game that has no meaning to me as an analyst
- Game Link – this also has no analytical value to me right now. I might use the game link later to get detail data for the plays of a game, but I’m not ready for that yet.
- Game Type
- Game Season
- Season Start
- Season End
- Game Venue
- Game Name
Simple statistics
Once I know whether a variable is numerical or categorical, I can compute statistics appropriately. I’ll be delving into additional types of statistics later, but the very first, simplest statistics that I want to review are:
- Counts for a categorical variable
- Minimum and maximum values in addition to mean and median for a numerical value
To handle my initial analysis of the categorical variables, I can add new measures to the model to compute the count using a DAX formula like this, since each row in the games table is unique:
Game Count = countrows(games)
Then I can set up a series of tables to list the counts for each category applicable to a categorical variable:
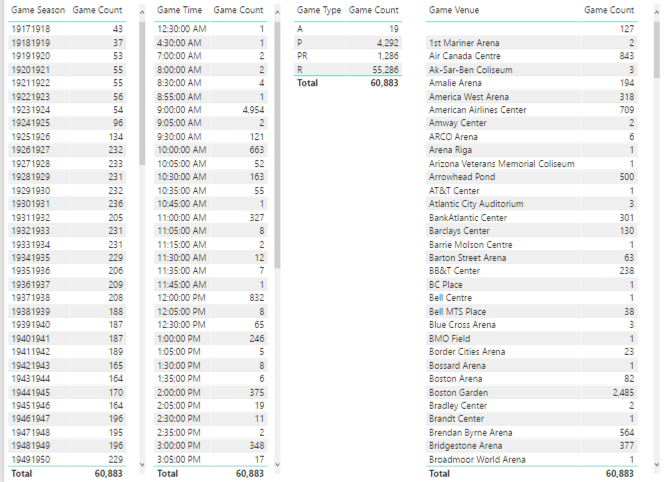
For the numerical variables, I need to add the variable to a table visualization. Then I can right-click on the field name assigned to a visualization and change the aggregation from the default of Sum to something else, like Minimum.
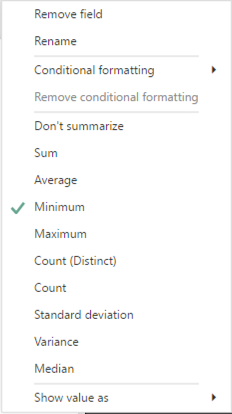
Next, I add the same measure to the visualization three more times and then reset the aggregation function for each addition so that I can also see its Maximum, Average (another name for Mean), and Median.
The main thing I want to do with this first pass at simple statistics for the games table is to perform a sanity check:
- Does anything look odd?
- Do I have fewer or more categories than expected?
- Is the range of numeric values reasonable or could there be outliers?
Here’s what I notice immediately:
- There are 127 games without a venue.
- The number of games per season seems to be increasing over time. Probably more teams were added over time which resulted in more games. However, as I scroll through the values, I see a significant drop in the number of games in the 1994-1995 and 2012-2013 seasons.
- There is an interesting spread of start times for games, such as 12:30 am or 4:30 am. Really?
- There are venues for which only 1 game was played, or a really low number.
These characteristics mean I need to look at the game table specifically to determine whether I think the data is accurate. If I find an issue, I’ll need to determine how best to fix it. “Best” really depends on how I intend to use the data.
I’ll repeat this process of creating table visualizations of categorical and numerical variables for the other tables in the Power BI model. You can review the results here on pages 3 through 12 of my report:
Some fields I didn’t evaluate – such as birthdate, names, and player id in the players table because the number of categories is either the same as the number of players or very close to that number. These are referred to as high cardinality categorical features, which are probably not useful for analytics in the current set of data.
On the other hand, current age is a useful substitute for birthdate. Furthermore, it’s interesting to review both as a categorical and a numerical variable.
In the statistics table, there are variables like evenTimeOnIce and powerPlayTimeOnIce that are also high cardinality. I’m going to evaluate these time-based variables differently in a future post.
I’ll introduce an alternative method for initial exploratory data analytics in a future post. Stay tuned! Lots of future posts to come! In the meantime, my next post starts to address issues that I see in the data.
4 Comments
[…] Stacia Varga digs into her hockey data set a bit more: […]
[…] to use various techniques to explore, enhance, and understand this data. I have enough data now for Part 3 of this series in which I can start performing some basic data exploration to begin to understand what I have […]
[…] I mentioned in my last post, I am currently in an exploratory phase with my data analytics project. Although I would love to […]
[…] Exploring the data to identify numerical and categorical variables […]